|
sysrepo
4.2.5
YANG-based system repository for all-around configuration management.
|
|
sysrepo
4.2.5
YANG-based system repository for all-around configuration management.
|
Sysrepo is a YANG-based datastore for Unix/Linux systems. Applications that have their configuration modelled using YANG can use Sysrepo for its management.
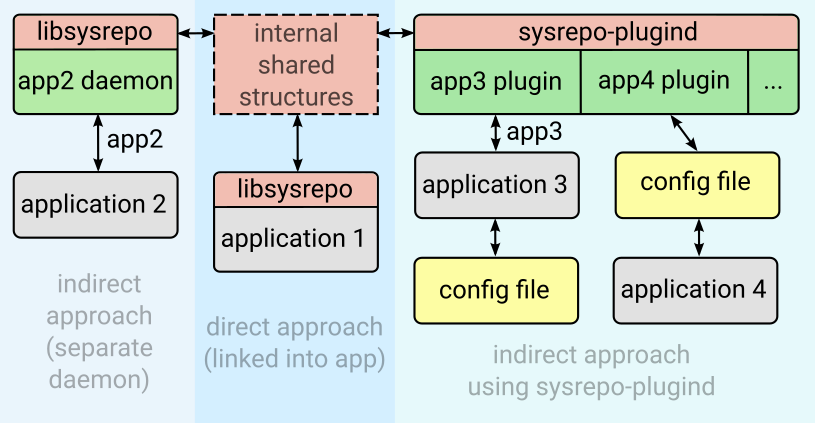
There are 2 main approaches for applications to make use of Sysrepo. The direct approach involves calling Sysrepo functions from the application itself whenever configuration data are needed or executing specific callbacks to react to configuration changes. It is also possible to implement a stand-alone daemon that will translate Sysrepo calls to actions specific for the application. This indirect approach is usually simpler to employ for existing applications because then they do not need to be changed themselves to utilize Sysrepo datastore at the cost of having an additional intermediary process (daemon). If there are several such daemons, they can be written as plugins and then all managed by one process.
poll(2)/select(2) to automatic thread handlers creation (more in threading)Main Sysrepo features are manipulation with YANG data and subscribing to various events. However, before any operation can be performed, a connection and session needs to be created and all the supported YANG schemas installed. Sysrepo can also keep records of its behaviour if logging is configured. Finally, despite being only a library, there are a few auxiliary utilities that use the API in some common ways.
Almost all API functions that work with data have 2 variants, each accepting the data in another format. An array of sr_val_t values can be used. This format is a legacy one and should generally not be used in new applications. However, there are specific use-cases when this format can be efficient so it was kept. The alternative is using native libyang tree structures (API functions suffixed with _tree()) that Sysrepo always works with internally. It has the advantage of generally being more efficient (no internal conversion is needed) and having an extended libyang API available for creating/modifying/printing.
Editing data is simple but requires basic knowledge of XPath for addressing individual data nodes. Getting data also uses XPath but for this purpose almost any valid expression can be used. If an exlusive access to certain data is required, locking is available.
The most common and useful kind of subscriptions are change subscriptions, which allow applications to perform actions based on specific data changes using callbacks. This way Sysrepo acts as a smarter configuration file. In addition, RPC/action and notification subscriptions are supported so that a specifc RPC can be executed and other Sysrepo clients can be notified about various generated events, respectively. It is also possible to expose some state data using operational subscriptions that are only for reading. These subscriptions, however, allow much more in order for NMDA operational datastore to be fully supported with all of its properties.
Datastores mostly follow the architecture defined by Network Management Datastore Architecture (NMDA RFC). Specifically, startup, running, candidate, and operational datastores are implemented in full compliance to the definitions. Following is a brief description and purpose of each datastore.
Startup datastore is the only persistent datastore. It includes the configuration of devices at time of their boot. This configuration is copied into running when the first Sysrepo connection (shared memory) is created after system boot.
Running datastore holds the current system configuration. This datastore is edited when a configuration change occured and a device should reconfigure itself. It does not persist across reboots. If desired, it can be copied into startup to rectify this.
Candidate datastore is meant to be a place to prepare configuration data without impacting the actual device. Be careful, because the actual use of this datastore is not restricted so it does not behave strictly according to NETCONF definition and follows general datastore rules instead (more in Editing Data). The specific features implemented are following. This datastore can be invalid and mirrors running datastore until it is modified. After that it can be reset to this behavior again only by calling sr_copy_config(). Also, sr_lock() will fail if a session tries to lock this datastore after some changes on it are performed. Finally, whenever sr_unlock() is performed for whatever reason (session termination), the datastore is also reset to its default state (mirroring running).
Operational datastore maintains the currently used configuration. Details about what exactly it is supposed to represent can be found in the NMDA RFC. In short, it should generally correspond to the current operational state and actual behavior of the system. In practice it includes data from running with some notable differences. Also, only this datastore includes any state data nodes.
By default, this datastore is empty. From user perspective, this is how data becomes a part of this datastore:
Note that all notification and RPC/action invocations are validated against this datastore.
Sysrepo also supports the NMDA origin attribute that appears only in the operational datastore. It is added automatically to all operational data; nodes that do not have their own inherit origin from their parents. However, whenever an application is providing/modifying operational data, it can set a specific origin that will be stored.
These data are found in the operational datastore and the following information applies to all operational data, both state and configuration nodes. Applications can provide them in 2 ways, pull or push.
If employing the pull method, the operational data are always retrieved when they are needed so they are guaranteed to be up-to-date. An application can subscribe to providing these data using an operational subscription. This method is suitable for data that change often such as some counters or statistics.
As for the second push method, its main principle is that the state data need to be set only when they change. They are stored and reused whenever needed without any interaction with the provider client but are owned by the session. This push method is suitable for data that do not change often or not at all such as network interface state or basic information about the system. Using this method to provide some specific operational data may be challenging because of a lack of many configuration data restrictions but there is a dedicated page explaining all the details and possible issues.
These methods can be combined and provided data can overlap. There is an example oper_pull_push_example illustrating providing the same data using both methods.
Firstly, regarding connections and sessions, a session is not synchronized at all so it must not be shared among multiple threads. Each thread should always create its own session to ensure correct behavior. Other than that there should be no restrictions and all Sysrepo API functions should be correctly synchronized for any number of processes, each with several threads.
As for subscriptions, they are fully synchronized but it makes no sense to process events of a single subscription in several threads (theoretically possible when SR_SUBSCR_NO_THREAD is used) because all events on a single subscription are handled sequentially. Also, processing events of a subscription while concurrently (in a different thread) modifying it (adding/modifying/removing subscribed events) may result in timeouts caused by deadlocks**. It is up to the application to divide its events-of-interest (all *_subscribe() calls) into individual subscription structures to allow their concurrent handling (such as reacting to configuration changes while notifications are being received).
Every subscription can then be handled in various ways. It can be fully managed by Sysrepo and it will by default create a separate thread that will wait for events on the subscription and process them. But, if your application has a custom event loop, for example, it can retrieve a file descriptor of a subscription that can be used in poll(2) or select(2) and use it to check for new events. Then, a handler function should be called that will process all pending events on the subscription. Alternatively, this handler can also be called periodically without any checking for new events.
Because Sysrepo uses shared memory, no automatic OS cleanup is performed in case an application crashes or does not properly terminate all its connections. There are mechanisms tracking the general state that allow to always recover correct state after a corrupt crashed application.
This recovery occurs whenever the particular state is being used (such as checking all relevant subscriptions when a new event is generated). Every recovery task should print warnings about what exactly is being recovered.
Sysrepo access control relies on file system permissions. Specifically, read and write permissions for specific modules are checked when an operation requiring them is being performed. This is always mentioned in the function documentation.
Permissions are checked for the session user that is inherited from the process owner that created the session. Changing it is possible if the process owner is root but should be done only if Sysrepo session is created by an application that delegates requests from other sources than the application itself (NETCONF, for example, more in sessions).
Schema-mount extension (RFC 8528) is supported. To use it, ietf-yang-schema-mount:schema-mounts operational data must be provided. Once set, this data is cached for future use. Using any of the methods will automatically work. Note: If you set new operational data, ensure the context is not acquired when performing the first operation afterward.
If you wish to use inline schema mount points, make sure to compile sysrepo without printed context support (-DPRINTED_CONTEXT_ADDRESS=0), because printed contexts currently only support shared mount points.
There are xpaths and paths used as parameters for various Sysrepo API functions. Generally, these are XPath expressions as used by YANG. Differences are outlined below. Note that there is often additional information about what is expected from the particular parameter.
XPath accepts any expression that libyang does. But libyang uses JSON module prefixes instead of XML prefixes of the module namespaces, which simply means that module names have to be used.
Path is similar to XPath defined above with some restrictions. It follows the JSON instance-identifier format meaning modules are strictly inherited from parents unless explicitly specified. Additionally, it is possible to use predicates to restrict nodes and wildcards can be used instead of node identifiers (* and .). Do not use spaces unless required (it is fine in literals enclosed in quotes).

